

Nachträgliches Update vom Tag danach unten angefügt
Eine massive Störung bei Amazon Web Services (AWS) hat am Montagmorgen weltweit für den Ausfall zahlreicher Online-Dienste gesorgt. Betroffen sind unter anderem Snapchat, PayPal, Supercell, Canva, , Roblox, Fortnite, Perplexity AI, Duolingo, Ubisoft, PlayStationNetwork, PrimeVideo, Alexa, Cloudflare, Amazon selbst und viele, viele weitere Plattformen welche AWS zumindest in Teilen für deren Infrastruktur nutzen.
Das Tochterunternehmen „Amazon Web Services (AWS)“ von Amazon ist als einer der weltweit führenden Anbieter von Hostingservices und Cloud-Diensten im Großen Stil. Dadurch stellt AWS im gesamten natürlich für einen Erheblichen Teil der bekannten Internetdienste Ressourcen bereit, was natürlich auch dazu führt, dass bei einer Störung von AWS dann gleich mehrere alltäglich-bekannte Apps, Dienste und Websiten in die Knie gehen.
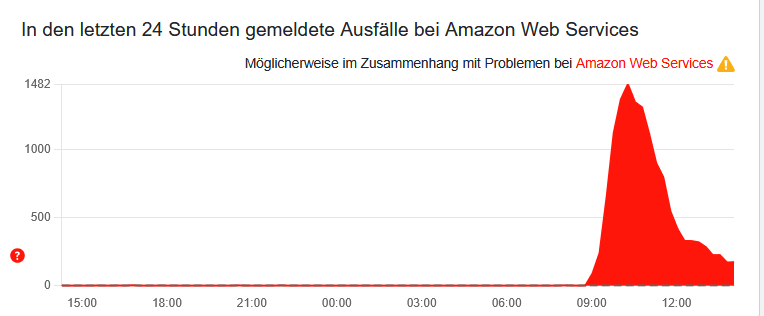
(Bild/Screenshot: https://allestörungen.de/stoerung/aws-amazon-web-services/)
Was sagt AWS zur Störung?
(Angepasst auf MESZ-Zeit und Übersetzt)
Auf der offiziellen AWS-Statusseite (health.aws.amazon.com) veröffentlichte das Unternehmen folgende Updates (Stand 20.10. 15:30Uhr):
Increased Error Rates and Latencies (Erhöhte Fehlerraten und Latenzzeiten)
20. Oktober, 14:48 MESZ
Wir machen Fortschritte bei der Behebung des Problems mit dem Start neuer EC2-Instanzen in der Region US-EAST-1 und können inzwischen in einigen Availability Zones (AZs) erfolgreich neue Instanzen starten.
Wir wenden ähnliche Maßnahmen auch auf die verbleibenden betroffenen Availability Zones an, um dort den Start neuer Instanzen wiederherzustellen. Während wir weiter Fortschritte machen, werden Kunden zunehmend erfolgreiche neue EC2-Starts beobachten können.Wir empfehlen weiterhin, neue EC2-Instanzen ohne feste Zuordnung zu einer bestimmten Availability Zone (AZ) zu starten, damit EC2 flexibel die passende AZ auswählen kann.
Außerdem möchten wir mitteilen, dass wir weiterhin erfolgreich den Rückstau an Ereignissen für EventBridge und CloudTrail abarbeiten. Neue Ereignisse, die an diese Dienste gesendet werden, werden normal verarbeitet und weisen keine erhöhten Übermittlungsverzögerungen auf.
Ein weiteres Update wird bis 15:30 Uhr MESZ oder früher bereitgestellt, falls neue Informationen vorliegen.
20. Oktober, 14:10 MESZ:
Wir bestätigen, dass die Verarbeitung der SQS-Warteschlangen über Lambda Event Source Mappings nun wiederhergestellt ist. Derzeit arbeiten wir daran, den Rückstau an SQS-Nachrichten in den Lambda-Warteschlangen abzuarbeiten.20. Okt, 13:08 MESZ
Wir arbeiten weiterhin an der vollständigen Wiederherstellung der EC2-Startvorgänge, bei denen derzeit möglicherweise ein „Insufficient Capacity Error“ auftritt. Außerdem arbeiten wir an der Behebung der erhöhten Abrufverzögerungen bei Lambda, insbesondere bei den Lambda Event Source Mappings für SQS. Ein weiteres Update erfolgt bis 14:00 MESZ.
20. Okt, 12:35 MESZ
Das zugrunde liegende DNS-Problem wurde vollständig behoben, und die meisten AWS-Servicevorgänge funktionieren nun wieder normal. Einige Anfragen können weiterhin gedrosselt werden, während wir auf eine vollständige Lösung hinarbeiten. Außerdem arbeiten einige Dienste weiterhin Rückstände auf, etwa CloudTrail und Lambda. Während die meisten Vorgänge wiederhergestellt sind, treten bei Anfragen zum Starten neuer EC2-Instanzen (oder von Diensten, die EC2-Instanzen starten, wie ECS) in der Region US-EAST-1 weiterhin erhöhte Fehlerraten auf. Wir arbeiten an der vollständigen Behebung. Falls weiterhin Probleme bei der Auflösung der DynamoDB-Service-Endpunkte in US-EAST-1 auftreten, empfehlen wir, den DNS-Cache zu leeren. Ein weiteres Update erfolgt bis 13:15 MESZ oder früher, falls neue Informationen vorliegen.
20. Okt, 12:03 MESZ
Wir beobachten weiterhin eine Erholung bei den meisten betroffenen AWS-Diensten. Wir können bestätigen, dass auch globale Dienste und Funktionen, die auf US-EAST-1 angewiesen sind, wiederhergestellt wurden. Wir arbeiten weiter an der vollständigen Behebung und werden Updates bereitstellen, sobald weitere Informationen vorliegen.
20. Okt, 11:27 MESZ
Wir sehen deutliche Anzeichen einer Erholung. Die meisten Anfragen sollten jetzt erfolgreich sein. Wir arbeiten weiterhin daran, aufgelaufene Anfragen abzuarbeiten. Weitere Informationen folgen.
20. Okt, 11:22 MESZ
Wir haben erste Gegenmaßnahmen umgesetzt und beobachten erste Anzeichen einer Erholung bei einigen betroffenen AWS-Diensten. Während dieser Zeit können Anfragen weiterhin fehlschlagen, während wir an einer vollständigen Behebung arbeiten. Wir empfehlen Kunden, fehlgeschlagene Anfragen erneut zu versuchen. Auch wenn Anfragen wieder erfolgreich sind, kann es zu zusätzlicher Latenz kommen, und einige Dienste müssen Rückstände abarbeiten, was zusätzliche Zeit in Anspruch nehmen kann. Wir werden weitere Updates bereitstellen, sobald neue Informationen vorliegen oder bis 12:15 MESZ.
20. Okt, 11:01 MESZ
Wir haben eine potenzielle Hauptursache für die Fehlerraten der DynamoDB-APIs in der Region US-EAST-1 identifiziert. Nach unserer Untersuchung hängt das Problem mit der DNS-Auflösung des DynamoDB-API-Endpunkts in dieser Region zusammen. Wir arbeiten auf mehreren parallelen Wegen an einer beschleunigten Wiederherstellung. Dieses Problem betrifft auch andere AWS-Dienste in US-EAST-1. Globale Dienste oder Funktionen, die auf US-EAST-1-Endpunkte angewiesen sind, wie IAM-Updates oder DynamoDB Global Tables, können ebenfalls betroffen sein. In dieser Zeit können Kunden möglicherweise keine Support-Fälle erstellen oder aktualisieren. Wir empfehlen, fehlgeschlagene Anfragen erneut zu versuchen. Ein weiteres Update erfolgt bis 11:45 MESZ oder früher, falls neue Informationen vorliegen.
20. Okt, 10:26 MESZ
Wir können erhebliche Fehlerraten bei Anfragen an den DynamoDB-Endpunkt in der Region US-EAST-1 bestätigen. Dieses Problem betrifft auch andere AWS-Dienste in derselben Region. Während dieser Zeit können Kunden möglicherweise keine Support-Fälle erstellen oder aktualisieren. Unsere Ingenieure wurden sofort hinzugezogen und arbeiten aktiv sowohl an der Behebung als auch an der vollständigen Ursachenanalyse. Ein weiteres Update erfolgt bis 11:00 MESZ oder früher, falls neue Informationen vorliegen.
20. Okt, 09:51 MESZ
Wir können erhöhte Fehlerraten und Latenzzeiten bei mehreren AWS-Diensten in der Region US-EAST-1 bestätigen. Dieses Problem kann auch die Erstellung von Support-Fällen über das AWS Support Center oder die Support API beeinträchtigen. Wir arbeiten aktiv an der Behebung des Problems und der Ermittlung der Ursache. Ein weiteres Update erfolgt in etwa 45 Minuten oder früher, falls neue Informationen vorliegen.
20. Okt, 09:11 MESZ
Wir untersuchen derzeit erhöhte Fehlerraten und Latenzzeiten bei mehreren AWS-Diensten in der Region US-EAST-1. Ein weiteres Update erfolgt innerhalb der nächsten 30–45 Minuten.
Diese AWS-Dienste sind betroffen
Laut dem aktuellen Statusbericht von 15:30 Uhr (MEZ) sind 83 AWS-Bereiche von der Störung betroffen:
Stark Beeinträchtigt:
- Amazon DynamoDB (als vermeintlicher Auslöser im Backbone)
Beeinträchtigt (65x):
- AWS Application Migration Service
- AWS Batch
- AWS CloudTrail
- AWS Config
- AWS Database Migration Service
- AWS Deadline Cloud
- AWS Directory Service
- AWS Elemental
- AWS Global Accelerator
- AWS Glue
- AWS HealthImaging
- AWS HealthLake
- AWS HealthOmics
- AWS IoT Core
- AWS Lambda
- AWS Outposts
- AWS Parallel Computing Service
- AWS Payment Cryptography
- AWS Private Certificate Authority
- AWS Secrets Manager
- AWS Site-to-Site VPN
- AWS Transit Gateway
- AWS Verified Access
- Amazon AppStream 2.0
- Amazon Athena
- Amazon Aurora DSQL Service
- Amazon Bedrock
- Amazon Chime
- Amazon CloudFront
- Amazon Cognito
- Amazon DocumentDB
- Amazon EMR Serverless
- Amazon ElastiCache
- Amazon Elastic Compute Cloud
- Amazon Elastic Container Registry
- Amazon Elastic Container Service
- Amazon Elastic Kubernetes Service
- Amazon Elastic Load Balancing
- Amazon Elastic MapReduce
- Amazon EventBridge
- Amazon FSx
- Amazon GameLift Servers
- Amazon GameLift Streams
- Amazon Interactive Video Service
- Amazon Kendra
- Amazon Kinesis Video Streams
- Amazon Location Service
- Amazon MQ
- Amazon Managed Service for Apache Flink
- Amazon Managed Service for Prometheus
- Amazon Managed Streaming for Apache Kafka
- Amazon Managed Workflows for Apache Airflow
- Amazon Neptune
- Amazon OpenSearch Service
- Amazon Pinpoint
- Amazon Polly
- Amazon Q Business
- Amazon Redshift
- Amazon Relational Database Service
- Amazon SageMaker
- Amazon Security Lake
- Amazon Simple Notification Service
- Amazon Transcribe
- Amazon VPC IP Address Manager
- Amazon WorkSpaces
Ist „xyz“ auch betroffen?
Solltest du gerade bei irgendeinem Service oder einer Website/App Probleme haben, kann auch das an der AWS-Störung liegen, da natürlich viele große Serviceanbieter in deren technischen Hintergründen auf Services der globalen Player wie Amazon, Microsoft, Google usw. setzen. Diverse Störungsmeldungen bekannter Dienste kannst du auf https://allestörungen.de/ abchecken, ob dort jeweils evtl. auch eine Störung vorliegt.
Wenn ja, kannst du anschließend unter https://health.aws.amazon.com/health/status den aktuellen Status bei AWS selbst einsehen.
-> Amazon bzw. AWS arbeitet selbstverständlich bereits intensiv an der Behebung des Ausfalls
Auf der oben erwähnten AWS-Statusseite schreibt Amazon (Stand jetzt: 14:25Uhr 20.10.) bereits von deutlichen Fortschirtten in der Fehlerbehebung, wodurch einige Dienste nun wieder als online und funktionstüchtig angezeigt werden. Auch andere Dienste kommen zum Teil wieder online – wenn auch AWS in deren Liveticker schreibt, gewisse Sachen immer noch erst einmal analysieren zu müssen.
Als „behoben“ aufgelistet von AWS sind:
- AWS B2B Data Interchange
- AWS CloudFormation
- AWS DataSync
- AWS Elastic Beanstalk
- AWS End User Messaging
- AWS Firewall Manager
- AWS IAM Identity Center
- AWS Identity and Access Management
- AWS IoT Analytics
- AWS IoT Events
- AWS IoT FleetWise
- AWS IoT SiteWise
- AWS NAT Gateway
- AWS Network Firewall
- AWS Organizations
- AWS Security Token Service
- AWS Step Functions
- AWS Storage Gateway
- AWS Support API
- AWS Support Center
- AWS Systems Manager
- AWS Systems Manager for SAP
- AWS Transfer Family
- AWS VPCE PrivateLink
- Amazon API Gateway
- Amazon AppFlow
- Amazon CloudWatch
- Amazon Connect
- Amazon DynamoDB
- Amazon EventBridge Scheduler
- Amazon GuardDuty
- Amazon Kinesis Data Streams
- Amazon Simple Email Service
- Amazon Simple Queue Service
- Amazon Simple Storage Service
- Amazon VPC Lattice
- Amazon WorkMail

(Bild/Screenshot: https://allestörungen.de/)
Was war los bei AmazonWebServices (AWS) am 20.10.2025?
(Update vom 21.10. Abends)
AWS hatte eine massive Störung der eigenen Dienste und mit Ihr brachen dann auch Dutzende von anderen weltweiten großen als auch kleinen Diensten zusammen:
AWS Störung vom 20.10.2025 – Was war los bei Amazon?
Hier nachträglich noch der von Amazon veröffentlichte „Abschlussbericht“: https://aws.amazon.com/de/message/101925/


Great article! We are linking to this great content on our
website. Keep up the great writing.